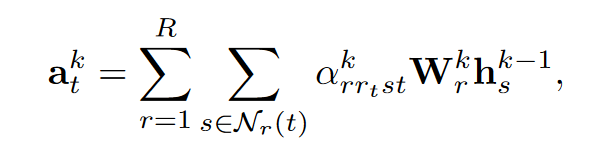GraiL-Inductive Relation Prediction by Subgraph Reasoning
huyi / August 2022
0.Abstract
-
previous work
dominant paradigm for relation prediction in KGs involves learning and operating on latent representations (i.e., embeddings) of entities and relations
-
problem of previous work
- these embedding-based methods do not explicitly capture the compositional logical rules underlying the knowledge graph
- limited to the transductive setting, where the full set of entities must be known during training
-
work of this paper
GraIL: reason over local subgraph structures and has a strong inductive bias to learn entity-independent relational semantics
–> outperforms existing rule-induction baselines in the inductive setting
–> complementary inductive bias
1. Introduction
-
task
link prediction
the relation prediction task can also be viewed as a logical induction problem
-
embedding-based methods
transE、rotatE、…
-
pros and cons
- Embedding-based methods have enjoyed great success by exploiting such local connectivity patterns and homophily.
- However, it is not clear if they effectively capture the
relational semanticsof knowledge graphs—i.e., the logical rules that hold among the relations underlying the knowledge graph.
-
-
naturally inductive methods
-
pros and cons
- One of the key advantages of learning entity-independent relational semantics is the inductive ability to generalise to unseen entities
- suffer from scalability issues and lack the expressive power of embedding-based approaches
-
3. Proposed Approach
-
key idea predict relation between two nodes from the subgraph structure around those two nodes
–> do not use any node attributes in order to test GraIL’s ability to learn and generalize solely from structure
–> only ever receives structural information (i.e., the subgraph structure and structural node features) as input
–> the only way GraIL can complete the relation prediction task is to learn the structural semantics that underlie the knowledge graph
-
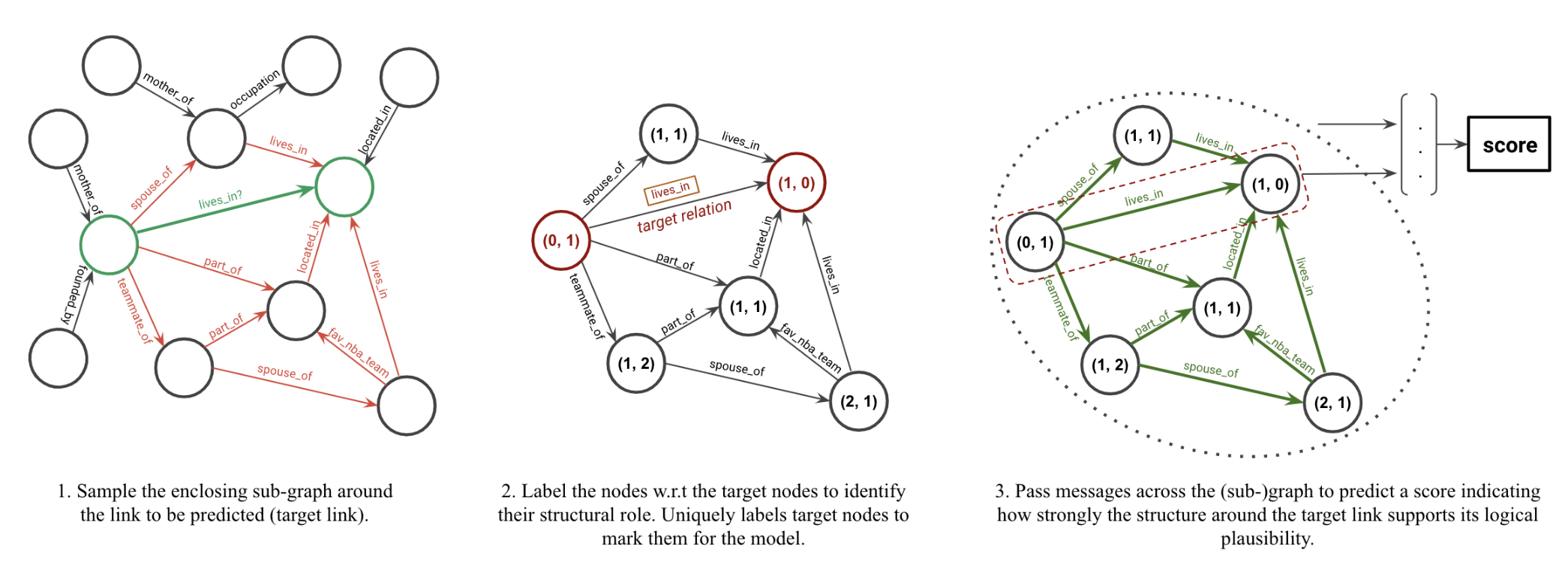
The overall task is to score a triplet (u, rt, v), i.e., to predict the likelihood of a possible relation rt between a head node u and tail node v in a KG, where we refer to nodes u and v as target nodes and to rt as the target relation.
-
总的任务可以分成三个sub-task:
-
- extracting the enclosing subgraph around the target nodes
-
- labeling the nodes in the extracted subgraph
-
- scoring the labeled subgraph using a GNN
-
3.1. Model Detail
Step 1: subgraph extraction.
we extract the enclosing subgraph around the target nodes.
-
enclosing subgraph between nodes u and v: the graph induced by all the nodes that occur on a path between u and v
- 具体步骤
- $\mathcal{N}_k(u)$ 和 $\mathcal{N}_k(v)$ 是两个 nodes 的 k-hop undirected neighbourhood.
- enclosing subgraph: $\mathcal{N}_k(u)\cap\mathcal{N}_k(v)$
- 这样取出来的 subgraph 当中连接 u 和 v 的路径最长是 k+1 这么长。(整条 path 都在 subgraph 当中)
- 注:
- 虽然在这个 extracting subgraph 的步骤中我们忽略了边的directions,但是在GNN 的 message passing 的过程中,还是看有向图的。
- the target tuple/edge (u, rt, v) is added to the extracted subgraph to enable message passing between the two target nodes.
Step2:Node labeling
- 子图中的i:用 (d(i, u), d(i, v)) 来label
- 其中 d(i, u) denotes the shortest distance between nodes i and u without counting any path through v (likewise for d(i, v)).
Step3:GNN scoring
用GNN来做scoring
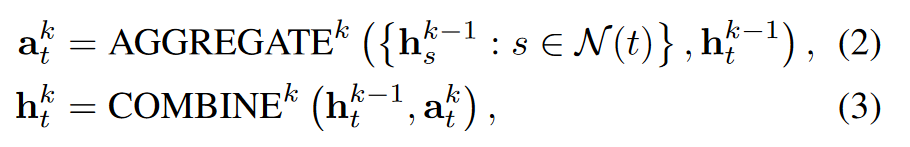
- AGGREGATE: