GreaseLM (2022 Jure Leskovec)
huyi / October 2022
1. INTRODUCTION
question
- QA requires reasoning over:
- stated context
- unstated, relevant world knowledge
- NLP 中的 QA paradigm:
- 过程:
- pretrained on extreme-scale collection of general text corpora
- fine tuned on domain-specific QA datasets
- performance:
- good on common benchmarks
- struggle when given examples that are distributionally different from examples seen during fine-tuning –> reason: learning on simple patterns rather than robust, structured reasoning
- 过程:
- KG: good in reasoning
how to integrate knowledge from KG with the context
- previous work
- fuse the two modalities in a shallow and non-interactive manner –> encoding both separately and fusing them at the output for a prediction, or using one to augment the input of the other.
remain an open question how to effectively fuse the KG and LM representations in a truly unified manner, where the two representations can interact in a non-shallow way to simulate structured, situational reasoning.
GREASELM
- exchange of information from both the LM and KG in multiple layers of its architecture
- LM + GNN
- LM input: natural language context
- GNN reason over the KG
- exchange:
每一层有一个双向的 information transfer
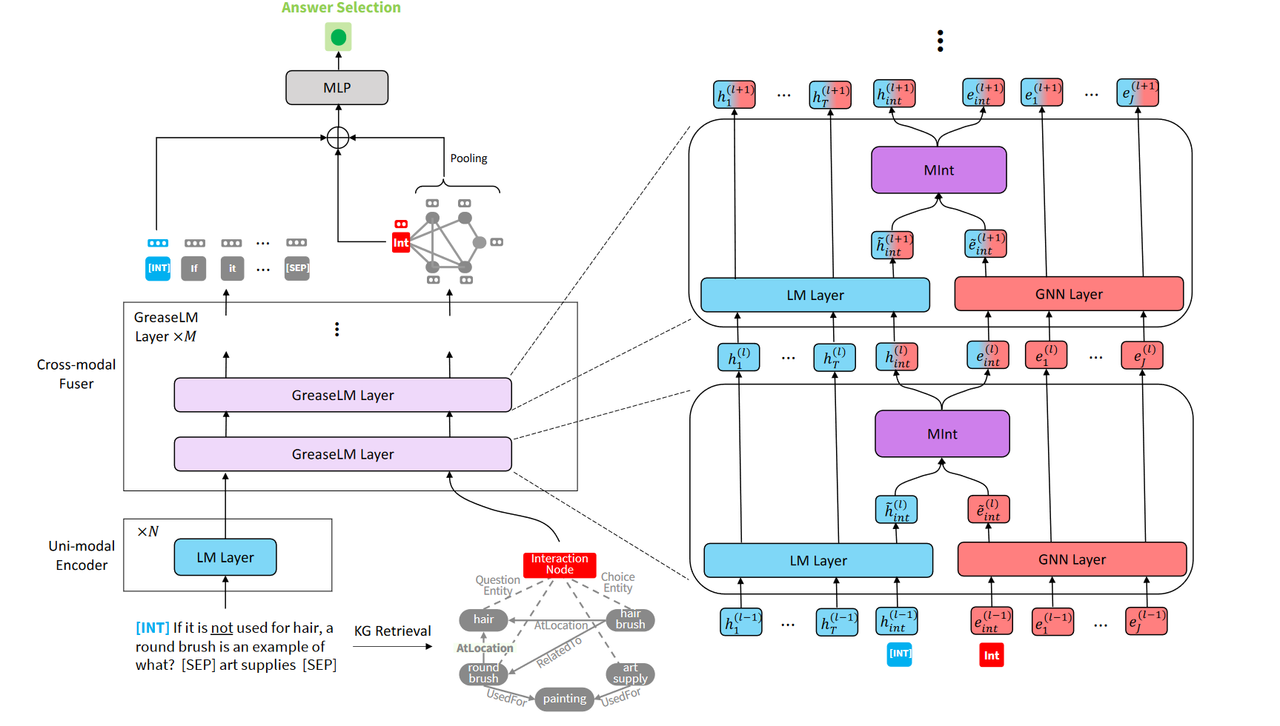
- LM + GNN
2. Related Work
integrating KG information for QA
earlier, previous work can be characterized into two classes:
-
use two-tower model: no interaction between LM & GNN
Improving natural language inference using external knowledge in the science questions domain.(2019) -
use one modality to ground the other
-
using an encoded representation of a linked KG to augment the textual representation of a QA example
Knowledgeable reader(2018)KagNet(2019)KT-Net(2019) -
use a representation of the text (e.g., final layer of LM) to provide an augmentation to a graph reasoning model over an extracted KG for the example
MHGRN(2020)
-
most recent, intergration of two models:
- access implicit knowledge encoded in LMs –> cons: discard the static KG once they train the LM on its facts, losing important structure that can guide reasoning
- join LM and GNN representation via message passing
–> cons: use a single pooled representation of the LM to seed the textual component of this joint structure, limiting the updates that can be made to the textual representation
5. GreaseLM
enabling representations of both modalities to reflect particularities of the other
- knowledge grounds language;
- language nuances specifies which knowledge is important.
- some works explore integrating knowledge graphs with language models in the pretraining stage –> cons: the modality interaction is typically limited to knowledge feeding language
3. Proposed Approach: GreaseLM
3.1 input representation
- input concatenate our context paragraph c, question q, and candidate answer a with separator tokens to get our model input [c; q; a] and tokenize the combined sequence into ${w_1, \cdots , w_T}$.
- use the input sequence to retrieve a subgraph of the KG($\mathcal{G}_{sub}$)
其中的nodes叫${e_1,\cdots,e_J}$
KG retrieval
given each QA context, 跟 QA-GNN 一样的 retrieval
interaction bottlenecks
a special interaction token $w_{int}$ and a special interaction node $e_{int}$
3.2 Language Pre-Encoding
In the unimodel encoding component: $l=0$,sum the token, segment, and positional embeddings for each token:${w_1, \cdots , w_T}$–>$h_{int}^{0},\cdots,h_T^{0}$. 之后过 N 层 LM-layer,用 transformer 架构.
3.3 GreaseLM
components:
- a transformer LM encoder block
- a GNN layer
- a modality interaction layer that takes the unimodal representations of the interaction token and interaction node and exchanges information through them
Language Representation
transformer
Graph Representation
GAT
Modality Interaction
只对 interaction token 和 interaction node 过一个 MInt 层