transE
huyi / July 2022
[toc]
Abstract
-
TransE用来: relationships –> translation operating on the low-dimensional embeddings of the entities
-
优势: 当时 link prediction 在 two knowledge bases(KB,一种KG) 上做得最好
Introduction
图的表示方法: 一堆三元组(head,label,tail),表示 head 和 tail 这两个 entity 之间有 label 这个 relation
knowledge bases (KBs):
例如: Freebase1, Google Knowledge Graph2 or GeneOntology3
each entity of the KB represents an abstract concept or concrete entity of the world and relationships are predicates that represent facts involving two of them __本篇文章目的:__
model multi-relational data from KBs, with the goal of providing an efficient tool to complete them by automatically adding new facts, without requiring extra knowledge
Modeling multi-relational data
notion of locality for a single relationship:
-
有一些是 structural, 不依赖具体的entity。比如说朋友的朋友也是我的朋友
这个其实也不一定, 是不是relation多多少少都是依赖entity的?例如上次组会上学长举的例子:“父亲的配偶是母亲”这个事情就依赖于社会环境/家庭状况之类的entity feature -
有一些 depend on entities: such as those who liked Star Wars IV also liked Star Wars V, but they may or may not like Titanic
难点在于:the notion of locality may involve relationships and entities of different types at the same time –>modeling multi-relational data requires more generic approaches that can choose the appropriate patterns considering all heterogeneous relationships at the same time
现在方式的缺陷:
- 复杂度高:The greater expressivity of these models comes at the expense of substantial increases in model complexity which results in modeling assumptions that are hard to interpret, and in higher computational costs.
- 容易overfitting/underfitting
Relationships as translations in the embedding space
TransE, an energy-based model for learning low-dimensional embeddings of entities.
-
从树结构得到启发:
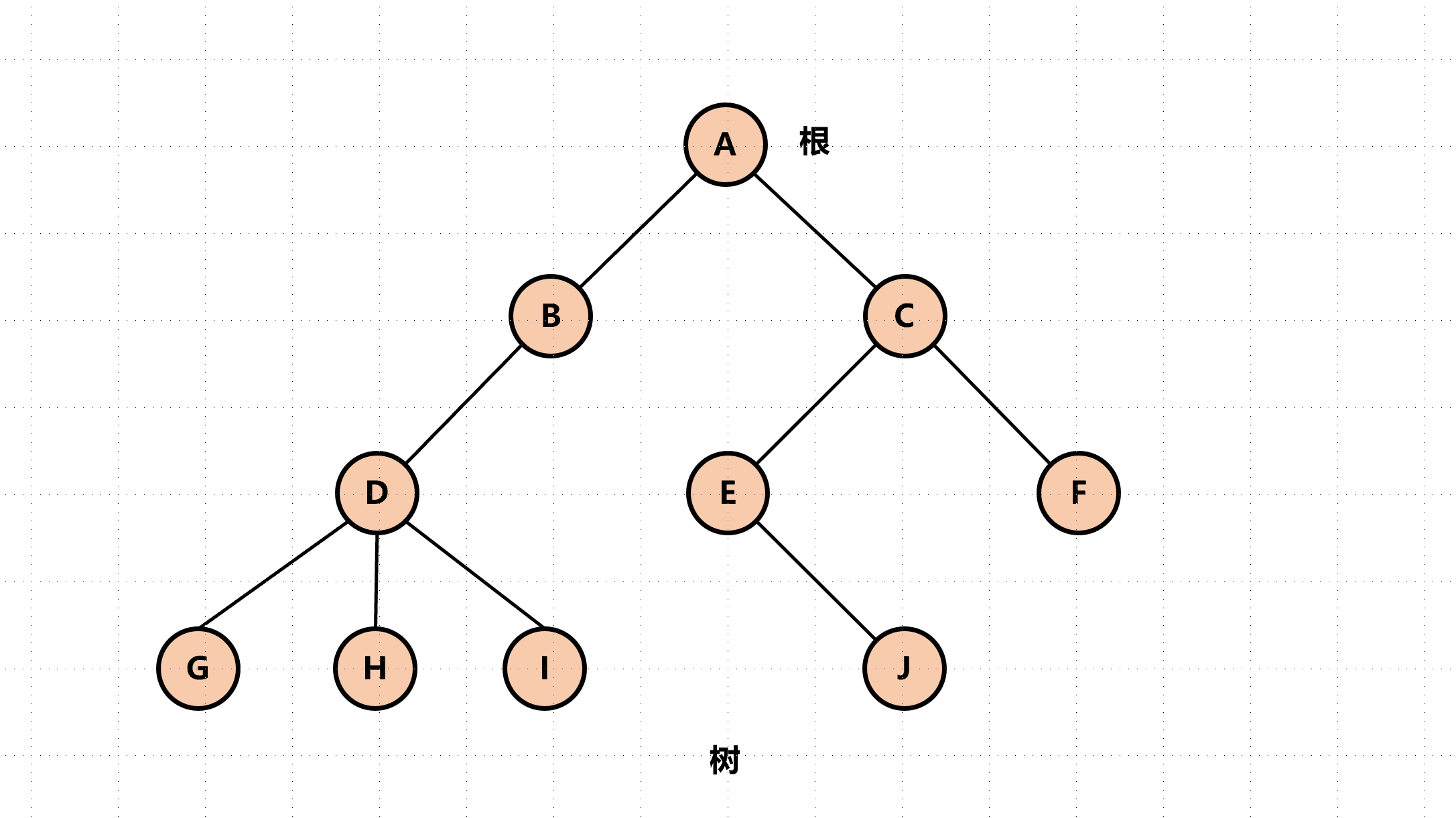
parent-child relationship相当于y轴上的一个平移
-
从一个word embedding的工作得到启发:
1-to-1 relationships between entities of different types may, as well, be represented by translations.
Translation-based model
-
learn 什么? vector embeddings of the entities and the relationships
-
结果期望: 若训练dataset中有(h, l, t), t should be a nearest neighbor of h + l
-
损失函数:
? 为什么损失函数长这个样子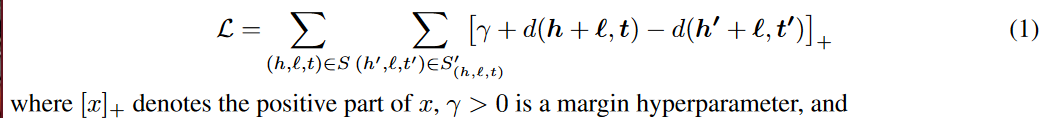
后面的distance表示的是h和l中至多有一个被换掉了,换掉以后希望他们之间的距离尽量大,所以后面这个是负号
? 后面的这个写的是不是有点粗糙,包含了很多存在于训练集里面的(h',l,t')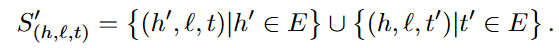
-
具体算法:
