watermellon book
huyi / July 2022
[toc] —-
chap1 绪论
1.1 引言
- learning algorithm: 从数据中产生模型的算法
- 有些文献用“模型”指全局性结果,e.g.决策树;用“模式”指代局域性结果。
1.2 基本术语
-
数据集 dataset:
很多个事件/对象对应的数据
e.g.(色泽:绿,敲声:响),(色泽:绿,敲声:响)
-
示例 instance/ 样本 sample: 数据集中关于一个事件/对象的描述
-
属性 attribute/ 特征 feature:
反映事件或对象在某方面的表现或性质的事项
e.g. 色泽,敲声
-
属性值 attribute value
-
属性空间(attribute space)/ 样本空间(sample space) 把attribute作为坐标轴,则它们张成一个用于描述对象空间,每个对象对应这个空间中的一个点,一个instance称为一个特征向量(feature vector)
- $D={x_1,x_2,…,x_m}$表示有m个示例的数据集,每个示例由d个属性描述,$x_i=(x_{i1};x_{i2},…,x_{id})$.
- d是x_i的 维数
- hypothesis–>ground truth
- label
-
样例 example:
有 label 的 sample,一般用$(\textbf{x}_i,y_i)$表示第i个样例
- 标记空间$y_i \in \mathcal{Y}$
-
classification
预测值是离散值
- binary classification
- multi-class classification
-
regression 预测值是连续值
-
clustering unsupervised 的代表。
前两个任务是supervised的代表
1.3 假设空间
- 机器学习是 归纳学习(inductive learning)
- 广义的归纳学习:从样例中学习
- 狭义的归纳学习:概念学习/概念形成
- 最基本的: 布尔概念学习
- 可以把学习过程看作一个在所有 hypothesis 组成的空间中进行搜索的过程,搜索目标是找到fit training set 的 hypothesis
- 可能可以找到多个和训练集一致的 hypothesis –> 假设集合 –> 版本空间 version space
1.4 归纳偏好
? 要解决的问题:如何在版本空间中进行选择 ? –> 归纳偏好 inductive bias:机器学习算法在学习过程中对某种类型假设的偏好
- 一般性原则来引导算法建立正确的偏好:
- 奥卡姆剃刀原理
需要注意奥卡姆剃刀原理有着在不同情况下有着不同的诠释,譬如说两个看起来差不多的假设哪个更简单这个问题,在不同模型中是不一样的
- 奥卡姆剃刀原理
- NFL定理 (No Free Lunch Theorem
 )
)
假设样本空间 $\mathcal{X}$ 和假设空间 $\mathcal{H}$ 都是离散的。令 $P(h|X,\mathcal{L}a)$ 代表算法$\mathcal{L}_a$ 基于训练数据$X$产生假设h的概率,再令f代表我们希望学习的真实目标函数。$\mathcal{L}_a$的训练集外误差: [E{ote}(\mathcal{L}a|X,f)=\sum\limits{h}\sum\limits_{x\in\mathcal{X}-X}\mathbb{I}(h(x)\neq f(x))P(h|X,\mathcal{L}_a)]
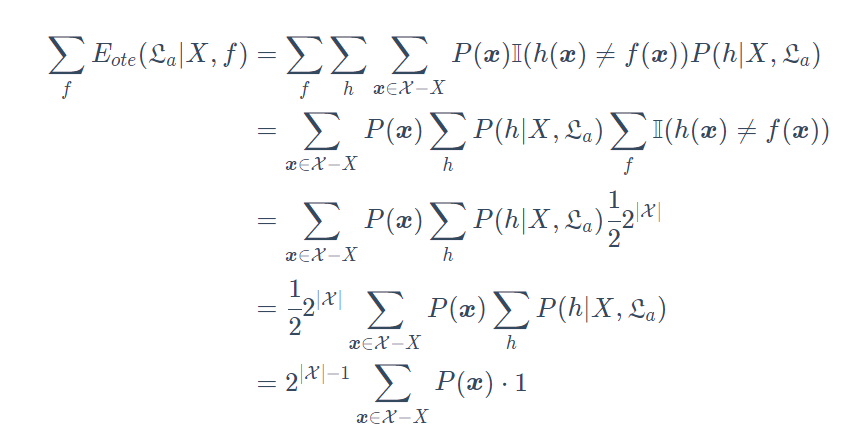
 f 作为希望学习的真实目标函数,在这边取所有的可能函数,这并不能说明所有算法针对某一问题误差恒定,而是说,某个算法必不可能在所有问题上取得小误差,擅长一些问题便必然不擅长另一些 ~
f 作为希望学习的真实目标函数,在这边取所有的可能函数,这并不能说明所有算法针对某一问题误差恒定,而是说,某个算法必不可能在所有问题上取得小误差,擅长一些问题便必然不擅长另一些 ~上面的式子说明的问题是总误差与学习算法无关! –>脱离具体问题,空谈什么算法更好没有意义!
chap1 习题
1.1
| 编号 | 色泽 | 根蒂 | 声音 | 好瓜? |
|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 是 |
| 2 | 乌黑 | 稍蜷 | 沉闷 | 否 |
上述表格对应的版本空间?假设三个attributes都只有三种书上给出的取法?
![]() | 编号 | 色泽 | 根蒂 | 声音 |
| —- | —- | —- | —- |
| 1 | 青绿 | 蜷缩 | 浊响 |
| 2 | * | 蜷缩 | 浊响 |
| 3 | 青绿 | * | 浊响 |
| 4 | 青绿 | 蜷缩 | * |
| 5 | * | * | 浊响 |
| 6 | 青绿 | * | * |
| 7 | * | 蜷缩 | * |
这里假定不包含非A的操作。
| 编号 | 色泽 | 根蒂 | 声音 |
| —- | —- | —- | —- |
| 1 | 青绿 | 蜷缩 | 浊响 |
| 2 | * | 蜷缩 | 浊响 |
| 3 | 青绿 | * | 浊响 |
| 4 | 青绿 | 蜷缩 | * |
| 5 | * | * | 浊响 |
| 6 | 青绿 | * | * |
| 7 | * | 蜷缩 | * |
这里假定不包含非A的操作。
1.2
每个attribute:$3+3+1=7$,$777+1$
1.3
选择假设使得训练错误累计最小。
chap2 模型评估与选择
2.1 经验误差与过拟合
- 错误率 error rate: 分类错误样本数占总数的比例:$E=a/m$
- 精度 accuracy: $1-a/m$
-
训练误差(经验误差) training error/ 泛化误差 generalization error
- 实际训练中,我们通常只能找一个训练误差极小的learner,但通常经验误差很小的leaner很可能泛化误差不小
- 过拟合 overfitting/ 欠拟合 underfitting: 过拟合是无法避免的,只能尽量减轻–> $P\neq NP$
2.2 评估方法
2.2.1 留出法
把数据集分成两个互斥集合——训练集$S$ 和测试集$T$
- 需要保证测试集和训练集数据分布尽可能一致 –> 分层采样
- 一般用 $2/3$ 或 $4/5$ 的样本用于训练
2.2.2 交叉验证法(cross validation)
-
k折交叉验证 k-fold cross validation
- 先把数据集$D$分为k个大小相似的互斥子集。
- 每个子集数据分布尽量一致 –> 分层采样
- 每次用k-1个子集的并集作为训练集,剩下的子集作为测试集
- 这样就可以获得k组训练/测试集
- 可以进行k次训练/测试
- 最终返回k次测试结果的均值
- 叫 k折交叉验证 k-fold cross validation
- 通常用10(5,20)
-
p次k折交叉验证
- 将数据集$D$划分为k个子集有多种方式,随机使用不同的划分p次,最后的评估结果是p次交叉验证结果的均值
- 常用“10次10折交叉验证”
-
留一法 Leave-One-Out (LOO)
- 每一折里面只有一个sample
- 评估比较精确
- 但是训练复杂度在dataset比较大的时候比较高
2.2.3 自助法(bootstrapping)
适用于数据集较小,无法有效划分训练集和测试集的时候
2.2.4 调参与最终模型
validation set: 模型评估与选择中用于评估测试的数据集
2.3 性能度量 (performance measure)
给定样例$D={(\textbf{x}_1,y_1),…,(\textbf{x}_m,y_m)}$,需要量化f(x)与y的差别。
-
回归任务中,常用“均方误差”(mean squared error): [E(f;D)=\frac{1}{m}\sum\limits_{i=1}^{m}(f(x_i)-y_1)^2]
-
连续的均方误差[E(f;D)=\int_{x\sim D}(f(x)-y)^2p(x)\rm{d}x]
2.3.1 错误率与精度
对样例$D$,
- 分类错误率
- [E(f;D)=\frac{1}{m}\sum\limits_{i=1}^{m}\mathbb{I}(f(x_i)\neq y_i)]
- [E(f,D)=\int_{x\sim D}\mathbb{I}(f(x_i)\neq y_i)p(x)\rm{d}x]
- 精度
- [acc(f;D)=\frac{1}{m}\sum\limits_{i=1}^{m}\mathbb{I}(f(x_i)= y_i)=1-E]
- 连续谱情况也是$1-E$
2.3.2 查准率、查全率与 F1
问题:
- 检索出的信息中有多少比例是用户感兴趣的?
- 用户感兴趣的信息中有多少被检索出来了?
–> 查准率 precision、查全率 recall 下面这个表叫 二分类混淆矩阵
| 真实情况</th> | 预测结果</th> </tr > | |
| 正例 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |